Differential Privacy in the U.S. and Japan
Preliminary#
Differential Privacy Variants#
DP is often summarized as ‘adding noise,’ but in practice it’s a formal privacy guarantee with many variants and mechanisms, typically implemented by adding calibrated randomness to released statistics under a privacy-loss budget.
There are enormous variants, models, and mechanisms for DP. The following are the selected ones:
- Variants
- Privacy unit
- User-level vs event-level DP1
- Trust / deployment models
- Central DP
- Local DP
- Shuffled DP
- Algorithms & Mechanisms
- Laplace mechanism
- Gaussian mechanism
- Exponential mechanism (DP for selection / non-numeric outputs)
- Randomized response (bit/answer flipping)
- Correlated-noise mechanisms (e.g., matrix-style approaches)
- ML training
- DP-SGD (and related training methods)
- Synthetic data / model release
- DP generative models
For that reason, the claim that “DP failed” is best understood as an over-compressed conclusion that omits substantial nuance.
Evaluating DP’s success or failure solely through the most visible Census data products is an overly narrow basis for assessment.
Census Bureau & Their Products#
"The Secretary shall, in the year 1980 and every 10 years thereafter, take a decennial census of population as of the first day of April of such year, which date shall be known as the “decennial census date”, in such form and content as he may determine, including the use of sampling procedures and special surveys."3
Census Data Products: Overview#
Public Law 94-171 (P.L. 94-171)
- What it is
"Public Law (P.L.) 94-171, enacted by Congress in December 1975, requires the Census Bureau to provide states the opportunity to identify the small area geography for which they need data in order to conduct legislative redistricting." 4 - What’s in it (content scope)
It’s intentionally compact—focused on the core redistricting needs:- Race totals (P1)
- Hispanic/Latino by race (P2)
- Voting-age (18+) by race (P3)
- Voting-age (18+) Hispanic/Latino by race (P4)
- Group quarters population by major type (P5)
- Housing occupancy (H1)
- Geography / granularity
It is built to be usable at very small geographic levels (e.g., census blocks) and also supports state-specified “small area geography” through the Redistricting Data Program process described in §141(c). - Timing (context)
Federal law requires transmission within one year after Census Day. For 2020 specifically, the Census Bureau notes the 2020 Redistricting Summary Files were posted August 12, 2021 and released on data.census.gov September 16, 2021 (same data, different formats). Statutorily it’s one year, but the 2020 cycle was delayed (COVID + operational sequencing), so the Bureau publicly revised delivery dates.
Demographic and Housing Characteristics (DHC) File
- What it is
The DHC is a much broader “core detailed tables” release from the 2020 Census—used for general policy, planning, research, and operations (not just redistricting). The Census Bureau released the 2020 DHC (alongside the Demographic Profile) on May 25, 2023. 5 - What’s in it (content scope)
DHC goes beyond race/Hispanic/voting-age and includes wide coverage of:- Age and sex
- Race and Hispanic origin
- Families and households / relationship to householder
- Group quarters
- Housing characteristics (including items like occupancy and tenure)
Other Products
- Supplemental-DHC (S-DHC)6:
It provides a limited set of person–household “join” tables—i.e., tables that require linking person characteristics (age/relationship) to household characteristics (household type/tenure).- PHSafe: a specialized DP algorithm for joined person + household statistics. The Census brief explains why this is harder than protecting persons and households separately: once you publish linked household compositions, each person’s record influences others’ results, increasing disclosure risk.
- Detailed Demographic and Housing Characteristics (DDHC) Files A7:
It provides population counts and sex-by-age statistics for 1) detailed race/ethnicity groups and 2) American Indian and Alaska Native tribes and villages- SafeTab-P: a DP algorithm that protects Detailed DHC-A by combining: adaptive design (deciding how much detail to publish for a group in a geography), and noise addition + postprocessing.
Unlike TopDown products, SafeTab-P outputs are not required to aggregate “as expected” (e.g., counties may not sum to the state), and summing many units generally accumulates noise (i.e., gets noisier as you sum more terms).
- Detailed Demographic and Housing Characteristics (DDHC) Files B8:
It provides household type and tenure (owner/renter) statistics (including total household counts) for the same detailed race/ethnicity groups and AIAN tribes/villages as Detailed DHC-A.- SafeTab-H: the DP algorithm for Detailed DHC-B, and it’s tightly coupled to SafeTab-P9.
The National Academies report is discussing the 2020 product pipeline and notes that DDHC-B and Supplemental-DHC were still scheduled for later release (relative to the core DHC and DDHC-A) and that major design/feasibility issues—especially for person–household joins—forced drastic cutbacks such as dropping substate geography for S-DHC join tables.10
Release Timeline:
For DDHC-B and S-DHC, there isn’t a hard statutory deadline like there is for the P.L. 94-171 Redistricting file. As of May 31, 2023, the Census Bureau publicly stated that two remaining 2020 Census data products were planned for release in September 202411The Bureau later refined (and partly pulled forward) the dates:
- Detailed DHC-B: updated to Aug. 1, 2024 (and released then).
- Supplemental-DHC (S-DHC): released Sept. 19, 2024 (and described as the final 2020 Census data product).
TopDown Algorithm#
The TopDown Algorithm (TDA) is the U.S. Census Bureau’s Disclosure Avoidance System framework for producing 2020 Census privacy-protected outputs using differential privacy plus postprocessing for consistency. In the Bureau’s own description, the DAS “has two parts: differential privacy algorithms and post-processing,” and both happen within the TopDown Algorithm.12
What TDA Is Trying to Achieve#
TDA is designed to publish tabulations (and privacy-protected microdata derivatives) that:
- satisfy a formal privacy guarantee (the Bureau describes versions that satisfy pure DP or zCDP)
- remain internally consistent (nonnegative integer counts, totals add up across tables and geographies) rather than releasing mutually inconsistent noisy answers
- preserve certain invariants (specific statistics kept exact as a policy choice)
Pipeline (High Level)13#
-
Convert confidential microdata into a histogram representation In Census training materials, the Bureau explains the first stage as converting the confidential Census Edited File (CEF) microdata into a histogram (counts of each unique combination of geography × characteristics)

source:14
-
Take “noisy measurements” under a set privacy-loss budget
- the Bureau sets a privacy-loss budget and allocates it across queries and geographic levels.
- The algorithm answers key tabulation queries and adds random noise; the transcript notes that the Bureau moved from geometric (discrete Laplace-like) noise to (discrete) Gaussian-style noise and uses zero-concentrated DP (zCDP) accounting for efficiency.
- These noisy measurements can be inconsistent with each other and even negative.
-
Postprocess via constrained optimization to enforce consistency and invariants At each geographic level, TDA combines:
- the noisy measurements for that level,
- the invariants (kept exact),
- and structural/rule-based constraints, to find a nonnegative, internally consistent, integer histogram that best reflects the noisy measurements.
-
Traverse a geographic hierarchy (“geographic spine”) The Census brief explains that TDA runs along a nested hierarchy (the “spine”) from nation down to block (Nation → (Region/Division) → State → County → Tract → Block Group → Block), and processes smaller units only after the larger parent is processed—this is part of why it’s called “TopDown.”
- Start at the nation: create a protected national picture.
- Go to states: create protected state numbers that add up exactly to the national totals.
- Go to counties: create protected county numbers that add up exactly to each state total.
- Keep going down until blocks.
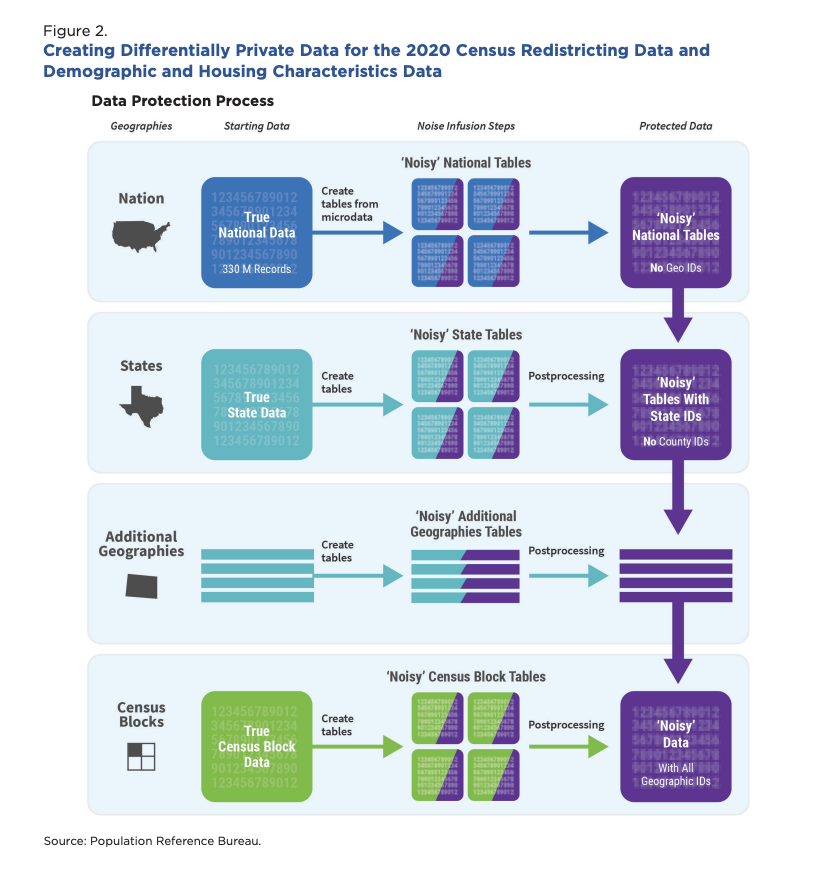
source:15
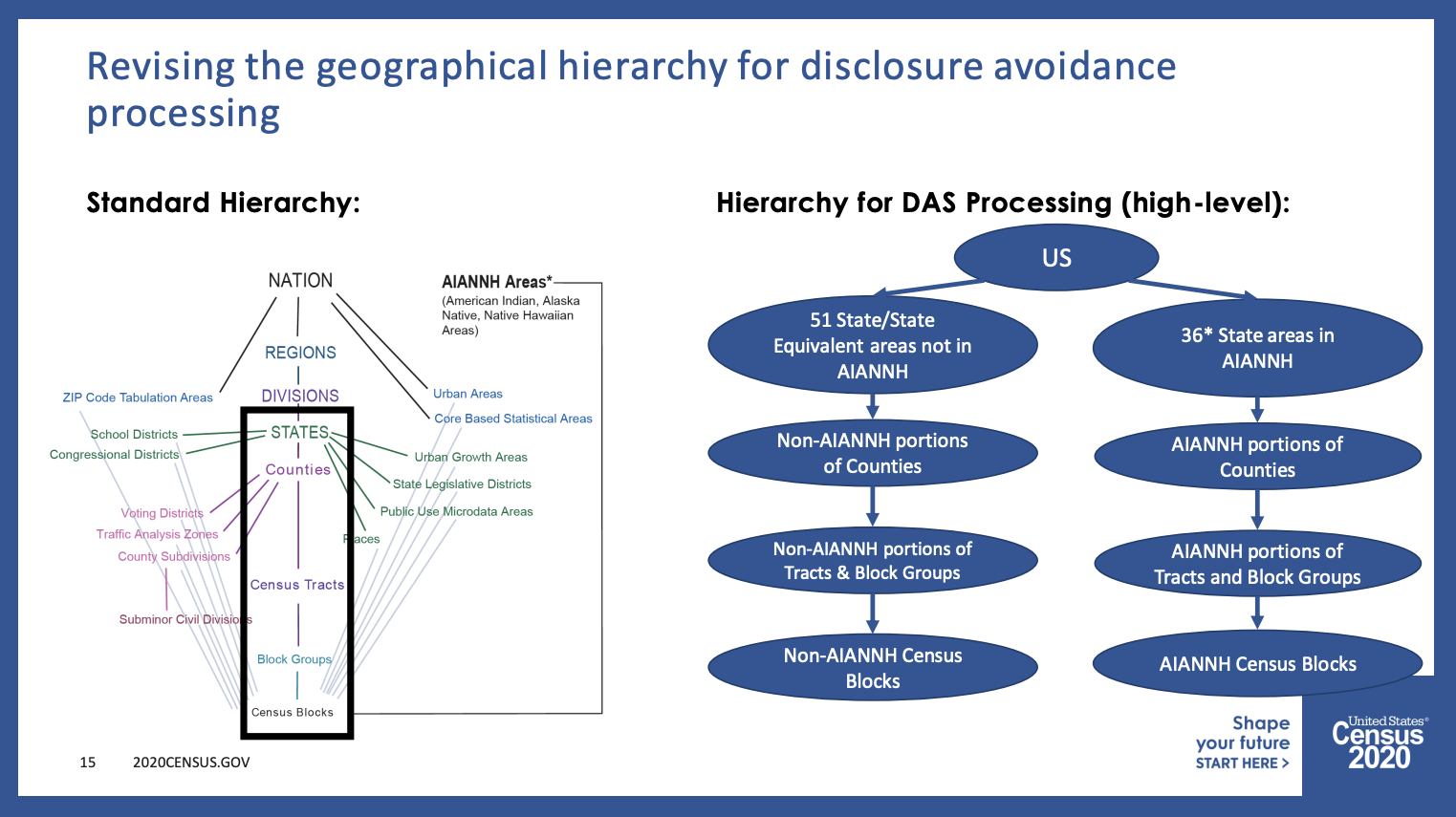
source:14
-
Convert the protected histogram back into microdata and tabulate "Finally, the TDA uses the noise-infused, postprocessed data to generate privacy-protected microdata records for the entire nation. The microdata include rows for each individual person or household and their characteristics for each geography. These individual records contain every level of geography on the Census Bureau’s geographic hierarchy. The records are exported into the Census Bureau’s tabulation system to generate published data products."15
Contexts; Why DP Was Employed?#
Reconstruction + re-Identification Risk Became the Central Threat Model#
They state that published tables are “increasingly vulnerable” to database reconstruction and reidentification attacks, describe their internal reconstruction experiment using published 2010 tables (noting those tables already had swapping applied), and report that they reconstructed a dataset of 300M+ individuals, then attempted matching against commercial data sources.16
Related materials from Census leadership (e.g., Abowd’s 2018 “database reconstruction theorem” talk) explicitly connect these reconstruction findings to the motivation to adopt differential privacy for the Census production pipeline.17
Georgetown's Work:
*Because this episode prompted me to dig into the topic in the first place, I note it here.
In 2012, the U.S. Census Bureau released a research report coauthored with Georgetown University researchers (Aditi Ramachandran and Lisa Singh) (plus collaborators at Census and Harvard) on re-identification risks in public data. The abstract’s key punchline is:
- Targeted re-identification using traditional variables can be feasible,
- but large-scale re-identification looked much less likely based on their case study. 18
However, a later Census Bureau summary of “reidentification studies” describes that 2012 effort as “not very successful” at linking ACS public-use microdata to an outside identified file, though they did have some success in a separate social-network linking exercise. 19
The same Census brief notes that the number/complexity of publications increased massively, citing that the 2010 Census released on the order of 150 billion statistics—exactly the environment where attackers can combine many tables to infer microdata.16
Traditional Techniques Didn’t Scale to that Threat Model#
Census explicitly contrasts DP with earlier approaches (swapping / suppression / rounding / category collapsing), saying traditional disclosure avoidance would require so much “noise” to defend against advanced attacks that data would become unfit for most uses—hence “the system had to be modernized.” They also say plainly that the relatively low swapping rate used in 2010 does not protect confidentiality, and that even very high swapping rates have limited ability to protect against re-identification attacks; plus swapping experiments can distort key distributions.16
A separate Census blog post (2019) summarizes the 2010 approach as “standard” disclosure avoidance such as swapping, coarsening, and suppression.20
The Census Bureau itself compares DP with legacy approaches (including swapping) and explains key limitations: under modern re-identification threat models, relying more heavily on suppression can quickly render data products unusable, among other issues.21
Alternatives to formal privacy:
This topic is outside the scope of this article; however, several alternative approaches exist.
source:22
2020 Census DP Controversy#
Disclosure Avoidance System (DAS) Development Timeline23#
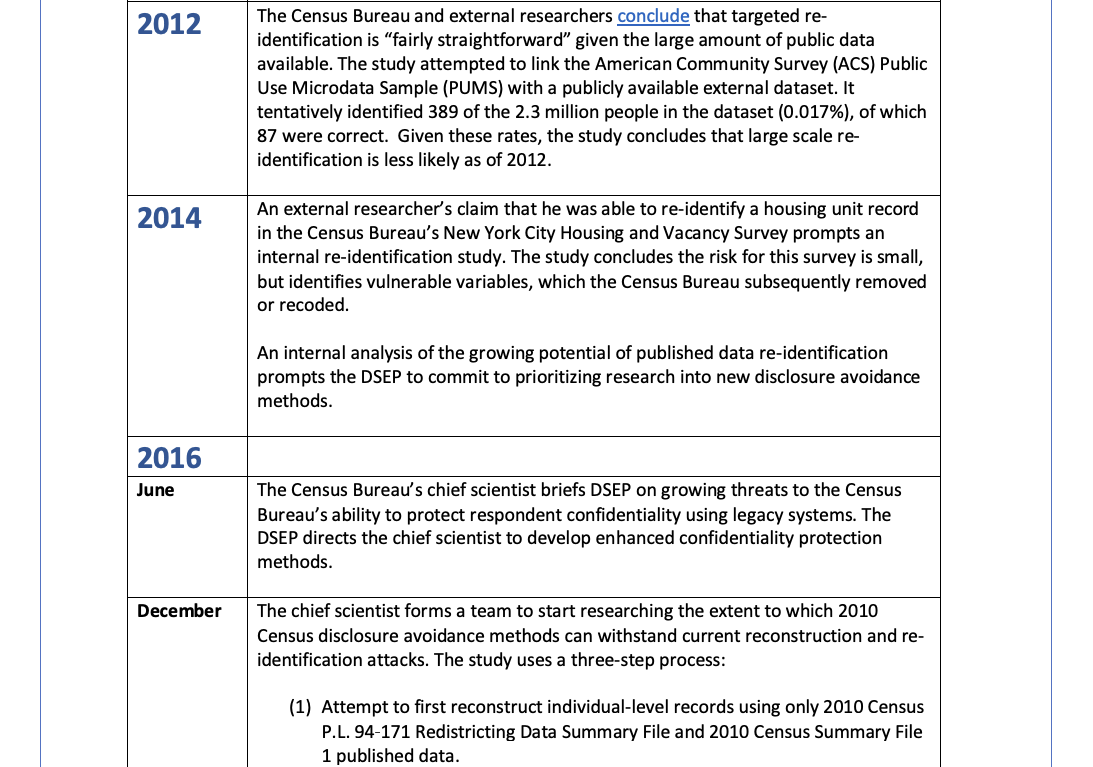
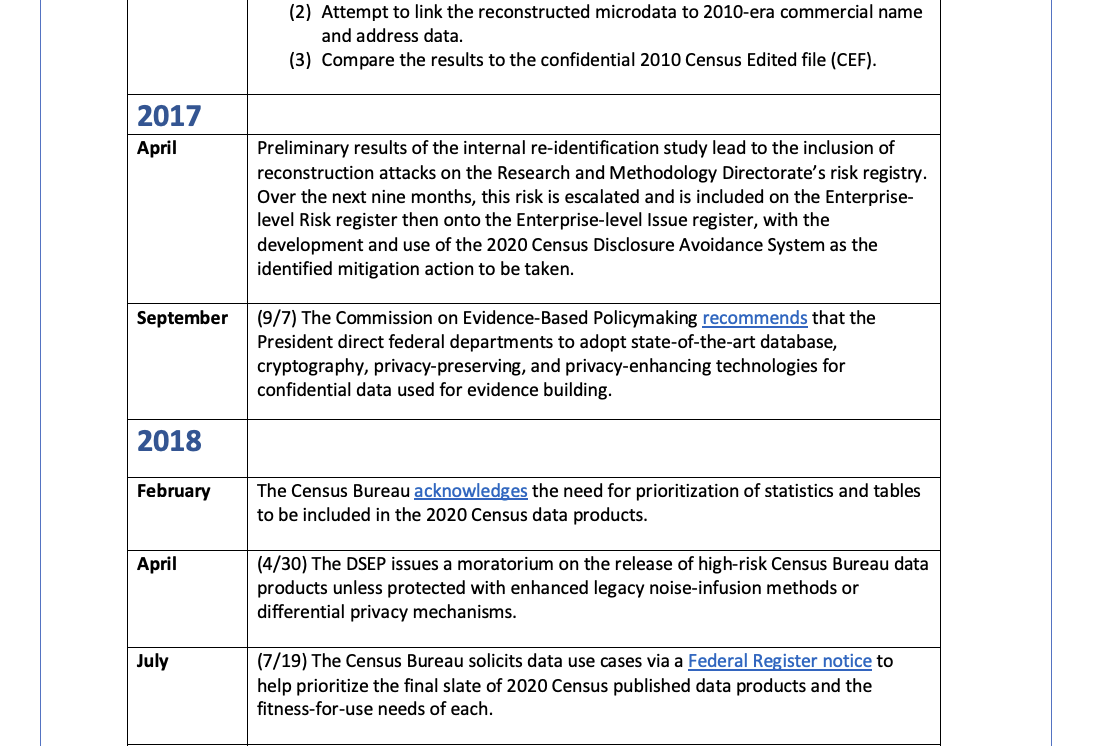
National Academies Report10, as an external review, also says:
"In the original plan, there was no indication that disclosure avoidance would require major changes to the delivery and content of data products. Nor had there been external pressure for changes in the disclosure avoidance method, akin to the complaints about costs, undercounts, and the quality of the Master Address File (MAF) or the calls for greater utilization of administrative records for data collection (see, e.g., National Research Council, 2004a, 2010, 2011)."
Late in the 2010s, the Census Bureau’s Research and Methodology Directorate proposed applying those new methods to the 2020 Census. The Census Bureau made a presentation to the Census Scientific Advisory Committee (CSAC) in fall 2016 that argued for a new approach for confidentiality protection; in a fall 2017 presentation to CSAC, the Census Bureau indicated it planned to use differential privacy-based algorithms to infuse noise into the 2020 Census data products (Abowd, 2016; Garfinkel, 2017).
"During 2016–2018, the Census Bureau simulated an “attack” on 2010 data products using commercial and publicly available data. The simulation involved first “reconstructing” individual-level records from 2010 published tabulations, then matching the commercial data (which contained name, address, sex, and age) to the reconstructed individual-level records on age, sex, and census block but not race or ethnicity. The Census Bureau estimated that 17% of the U.S. population could have their race or ethnicity identified with a high level of certainty based on comparing the matched commercial-reconstructed records to the actual responses in the CEF (which, however, an outside attacker could not do)."
Controversy Triggers: The 2020 Census Differential Privacy Controversy#
High-Level Overview#
The “DP controversy” around the 2020 U.S. Decennial Census can be understood as a breakdown in alignment across three distinct layers of authority and accountability:
- Policy authority (policy / social contract): the decision to move from legacy disclosure avoidance to formal privacy (differential privacy).
- Technical authority: the design of the disclosure avoidance system (DAS) and its constraints, and the product semantics it must uphold.
- Release authority: governance of scope, change control, and user-facing release execution under statutory timelines.
The controversy is less about whether differential privacy is “mathematically correct,” and more about how late-stage policy decisions, incomplete census-context testing, and weak release governance interacted to erode process trust—ultimately amplifying disputes during production release.
Policy Authority#
What Was Decided—and Why It Became Controversial
The Census Bureau adopted a threat model in which publicly released tabulations are exposed to reconstruction and reidentification risks, and concluded that 2010-era approaches were no longer sufficient. Based on this threat model, the Bureau decided to transition to a formal privacy framework (differential privacy) as the foundation for the 2020 Census disclosure avoidance system.
Multiple official and semi-official sources point to the same operational problem: the shift to differential privacy occurred late in the 2020 Census planning cycle, and that late policy commitment had predictable downstream consequences.102425
Why the Timing Mattered
Late adoption meant there was limited opportunity to:
- build and validate a full end-to-end implementation in a census production environment,
- run sufficient census-context testing and evaluation using realistic products and constraints,
- establish a credible backup plan in case the implementation or integration effort slipped,
- communicate proactively and interactively with the user ecosystem before major changes.
In other words, policy authority exercised a decisive shift toward DP under an urgent confidentiality narrative, but the timing constrained the organization’s ability to de-risk technical and release execution—making “release-stage turbulence” difficult to avoid.
Technical Authority#
What Technical Decisions Were “in Scope” for Controversy
Once DP became the policy commitment, technical authority effectively controlled (and became accountable for) a set of specification-level decisions that directly shape data usability:
- Privacy loss budget (e.g., ε / ρ) and its allocation across tables, geographies, and attributes (i.e., what is protected more vs. less).
- Constraint and postprocessing design, including:
- invariants / quasi-invariants,
- geographic hierarchy consistency,
- non-negativity and rounding,
- other feasibility constraints intended to prevent nonsensical outputs.
- Product semantics, especially the coupling between person and housing concepts (how far the system guarantees internally consistent relationships between people counts and housing-unit counts).
These choices are difficult in any DP deployment; in the census context, they become exceptionally visible because users often depend on fine-grained geographies, small subpopulations, and cross-tabulated products that must remain mutually coherent.
What Users Saw: Inconsistencies and “Implausible” Outputs
A recurring flashpoint was the appearance of outputs that violated common-sense constraints—particularly at very small geographies (e.g., blocks). Examples include:12
- a block with one occupied housing unit but dozens of residents (implausibly implying a single household contains all residents),
- a block with children under 18 but no adults present,
- a block with household residents despite only vacant housing units,
- a block with more occupied housing units than people to occupy them.
The Disclosure Avoidance Handbook explicitly acknowledges that noise infusion and subsequent processing can yield improbable results in redistricting data, and it reports that these inconsistencies disproportionately occur at very small geographic units.
These inconsistencies are disproportionately associated with very small population geographies. For example, the handbook notes that 4.8% of blocks with people living in households have zero occupied housing units, while the comparable inconsistency is about 0.1% at the block-group and tract levels.
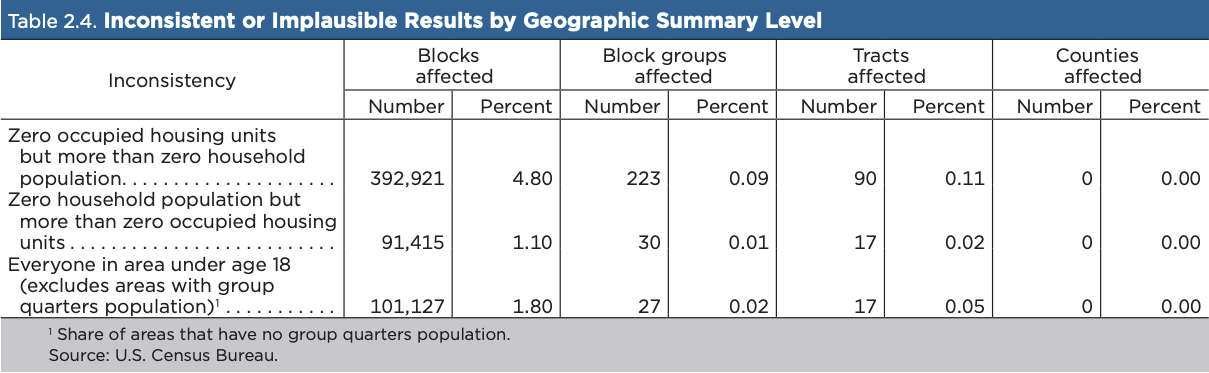
source:12
How the Controversy Propagated
This DP controversy was primarily a sustained dispute within the policy / research / redistricting ecosystem, with periodic spikes of mainstream-media attention, rather than a short-lived, broad public social-media firestorm.
- AP (2019):26
- Washington Post (2021):27
- AP (2021):28
- The Markup (2021):29
- San Francisco Chronicle (2021):30
- and extensive discussion across social media.

Release Authority#
Release authority is where the controversy became operationally visible: delays, iterative demos, scope shifts, and late-stage parameter changes under legal and stakeholder pressure.
Release Delay in 2020 (Compared to Other Years)
The National Academies summarize 2020 Census product preparation and release as not smooth or timely, noting that COVID-19 contributed to delays for early products (e.g., April 2021 reapportionment counts; August 2021 redistricting file). They also describe later downstream delays (e.g., DHC and subsequent products) as tied primarily to adopting formal privacy methods late, combined with insufficient census-context testing and the lack of a backup plan.
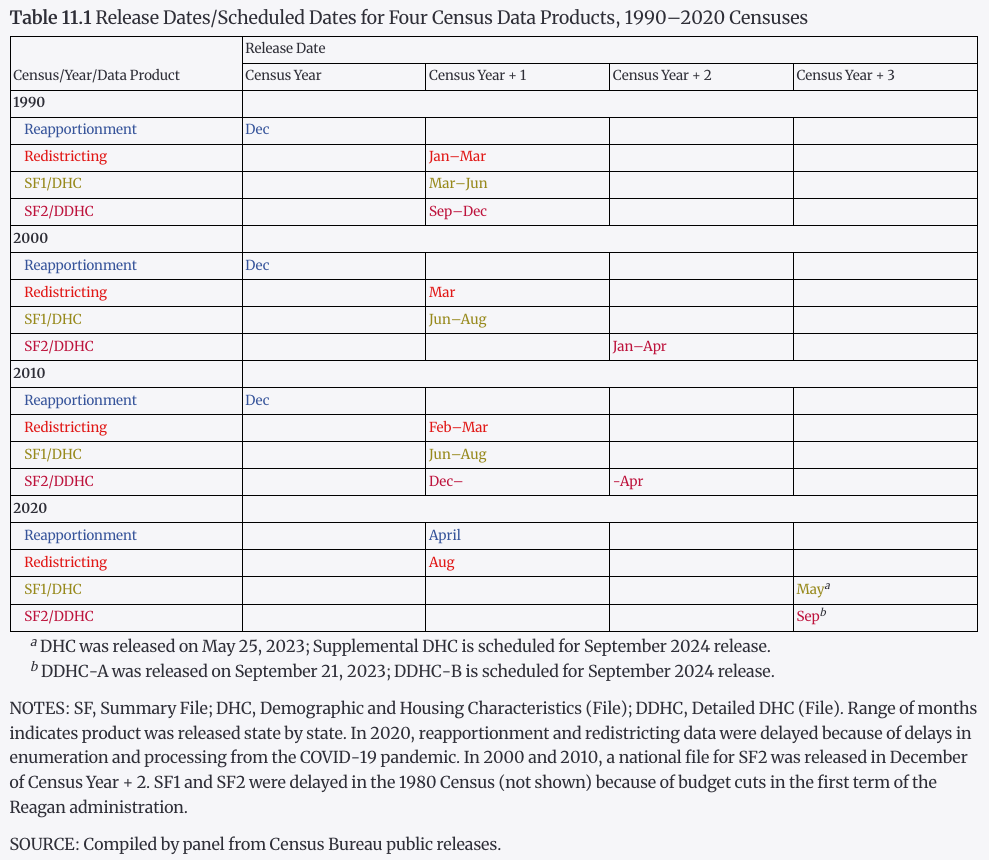
source:10
No Backup Plan
A detailed case study (Garfinkel) is explicit that the Bureau committed to Differential Privacy before having a fully working end-to-end implementation, and that there was no real backup plan if the approach could not be delivered in time for legally mandated publications.31
The same case-study framing also emphasizes that, because planning for the 2020 Census was already far along, the confidentiality-protection system became a late-stage bottleneck that had to be built and integrated quickly. The National Academies’ final assessment makes essentially the same point and ties it directly to operational consequences (delays and disruption).10
Demonstration Data Products (DDPs) and the Feedback Loop
Purpose. The DDPs were intended to let external users evaluate impact and failure modes by applying development-stage to near-production DAS / TDA (TopDown Algorithm) to already-released 2010 Census data—not to the 2020 production microdata—so users could assess “how much shifts” and “what breaks.” The Census Bureau also describes DAS development as iterative, requiring user engagement and feedback.
Observed issues in practice. The case-study critique highlights that the program iterated through multiple public “demonstration” releases that drew heavy criticism, and that the scope and settings of demos changed repeatedly.
Two recurring friction points are emphasized:
(A) Privacy budgets and late-stage changes
The critique notes:
- There were substantial changes between the final DDP and the official release.
- At least at the time, the method for determining the privacy loss budget was not publicly explained to a degree many stakeholders found adequate.
The “Developing the DAS” page describes how the Bureau provided demo metrics and evaluation materials (e.g., PPMF) for users to assess iterations, and states that the final settings were decided by the Data Stewardship Executive Policymaking Committee.32
(B) Mechanism changes (pure DP → zCDP)
Census technical documentation on the TopDown Algorithm reports that earlier demonstration releases used ε-based accounting, but by the September 2020 demonstration release (and later) the privacy-loss budget is reported in ρ, consistent with a shift to zCDP accounting.33
Related Census documentation explains that this corresponds to using (discrete) Gaussian-style noise (rather than geometric/discrete-Laplace-like noise), which reduces extreme outliers.1213
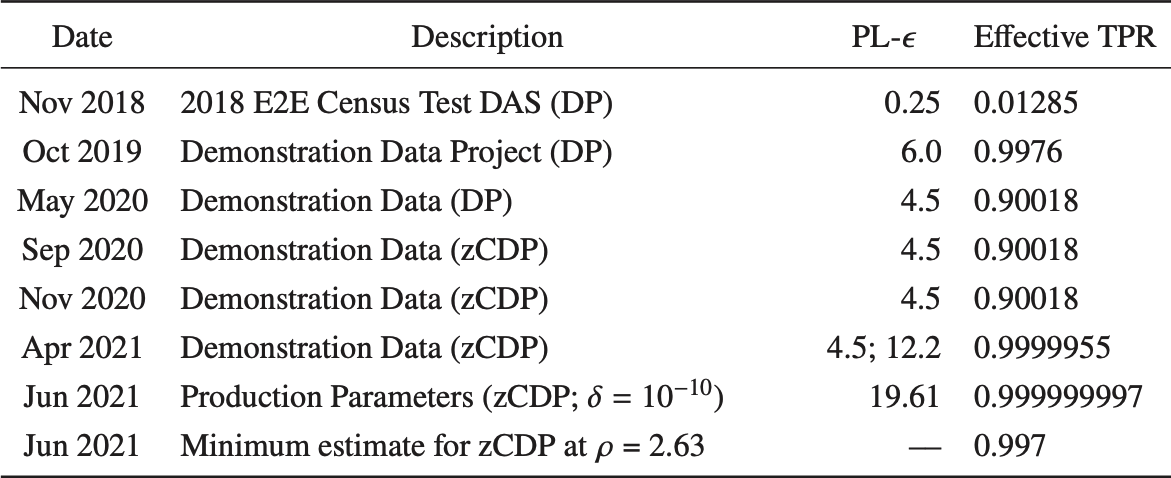
source:34
What Was Ultimately Lost:
The key failure mode highlighted here is not primarily “whether DP is mathematically correct,” but that the release process undermined trust in the official-statistics process—and that loss of process trust amplified the controversy.
Why People in the U.S. Say “DP Has Failed” (in the Census Context)#
Public claims that “DP has failed” around the 2020 U.S. Census are rarely about differential privacy (DP) as a mathematical framework in the abstract. They are much more often about (a) the specific DP-based Disclosure Avoidance System (DAS) the Census Bureau deployed, and (b) how governance, timelines, and communications shaped both product decisions and public interpretation.
DP is not a single monolith: it has many variants, design choices, and parameterizations. So the phrase “DP failed” is usually a shorthand for “this particular DP deployment, with this parameter tuning and product contract, did not meet key expectations.”
The Structural Story Behind the “DP Failed” Narrative#
A common causal chain looks like this:
- Delayed decision to adopt “formal privacy.”
- Insufficient time for contingency planning—including feasibility work and deep problem-framing for applying DP to Census data products.
- Design started under hard constraints (legal deadlines, operational schedules).
- The DP/DAS team faced the hardest part of the problem—allocating privacy budget across a complex portfolio of Census data products and sometimes narrowing product scope—under intense time pressure.
- The feedback loop looked messy from the outside (e.g., iterative parameter changes without a clean public narrative of why, what changed, and what tradeoffs were accepted).
- Release arrived before the Bureau’s explanations were fully absorbed, and many stakeholders felt blindsided.
- Media and social amplification converted technical disputes into a broad impression of “DP disappointment” or “DP failure.”
- Two opposing complaints emerged simultaneously—and reinforced each other:
- “DP is necessary, but these outputs are not usable.”
- “These outputs are usable, but privacy protection must have been weakened.”
In effect, governance and product-contract disputes were reframed as a verdict on DP itself.
This context matters: it explains why the debate often feels like a referendum on DP, even when the underlying issues are product design, scope, communication, and policy authority.
What the “DP Has Failed” Debate Is Actually About#
In practice, the core objections cluster into four families:
- Product failure for small areas / small groups: statistics are no longer “fit for use,” especially for small geographies and small population groups.
- Implausible / impossible results: outputs that violate common-sense or logical constraints are seen as unacceptable.
- Consistency problems: both within a product and across products (e.g., P.L. 94-171 vs DHC) where users expect aligned concepts to match.
- Protection-level concerns: accuracy increased (noise reduced) at the cost of weaker formal guarantees—raising “is privacy still strong enough?” questions.
Each section below explains the logic behind these critiques and why they persist even when the Bureau argues the results are “by design.”
1) the Small-Area / Small-Group “Unusable Statistics” Problem#
Census materials emphasize that prior disclosure avoidance approaches (including what was used for 2010) cannot be relied on indefinitely, given stronger external data and modern reconstruction/re-identification threats. Their explanation highlights that highly accurate block-level counts can become a key ingredient in reconstruction attacks under contemporary threat models.35
In other words, the historical tradeoff was always there:
- The old world often produced highly usable small-area statistics,
- but it did so while leaving meaningful disclosure risk on the table—and in some cases enabling attacks.
So some degradation in small-area utility is not an accident; it is the cost of shifting the privacy posture.
Why “It’s Unavoidable” Is Not a Complete Defense
Even if small-area degradation is an inherent tradeoff, the “unusable” outcome is not automatically excused—because there are official and semi-official benchmarks that treat small-area usability as central.
(A) The Bureau itself set “fitness-for-use” accuracy targets (for key legal uses)
The Census Bureau’s materials describe tuning the TopDown Algorithm (TDA) toward accuracy targets relevant to:
- P.L. 94-171 redistricting uses, and
- Voting Rights Act (VRA)-related uses. 35
They also describe setting concrete targets informed by DOJ-provided sample use cases (example target: largest racial/ethnic group accuracy within a margin at high probability for geographies above a population threshold).36
Key point: “Fitness-for-use” here does not mean universally high accuracy for all conceivable uses. It means meeting accuracy requirements for the institutionally central uses the Bureau is obligated to support (redistricting/VRA). That still creates an expectation: even if some uses are sacrificed, the major legal uses should remain viable.
The Bureau stated it could not deliver near-perfect block-level accuracy because it would undermine a functional disclosure avoidance system, while emphasizing legal and ethical obligations to protect respondent confidentiality.37
The fact sheet also provides usage guidance that block-level outputs are noisy and should often be aggregated for many applications.35
(B) National Academies frames small-area / small-group accuracy as a core Census value proposition
National Academies materials emphasize that Census data’s societal ROI comes from timely, accurate products for small geographies and population groups (including groups defined by race/ethnicity and other characteristics), describing Census as a uniquely reliable source for many small jurisdictions.10
From this viewpoint, “threats exist, therefore small areas can be less usable” is not the end of the conversation. Instead, “how much usability did you preserve while achieving protection?” becomes part of the evaluation criterion.
What this Implies About "DP Failed":
The claim “this DP deployment yielded unacceptable small-area utility for key stakeholders” is a legitimate product critique—especially given explicit “fitness-for-use” framing and the centrality of small-area data to Census value.However, when you account for the constraints that pushed the Census Bureau toward formal privacy in the first place, the shift to DP can still be seen as a broadly rational—if costly—choice.
2) Implausible / Impossible Results#
The Bureau’s Position: Some Inconsistencies Remain “by Design”
Census documentation describes imposing certain constraints in post-processing, while acknowledging that some inconsistencies can remain.
A Census brief (for DHC context) goes further by naming implausible / impossible results, explaining that:
- they are more likely in small populations / small geographies,
- some issues can be mitigated by aggregation,
- but some inconsistencies persist because the person file and housing unit file are protected separately, creating cross-file mismatches that aggregation will not necessarily fix (e.g., relationships between householders and occupied households).38
The handbook similarly emphasizes that:
- odd results are more frequent for small geographies,
- aggregation reduces frequency,
- block-level outputs are often too noisy for many uses, and
- users should apply appropriate handling and aggregation strategies. 12
Why stakeholders still react: “that’s unacceptable”
Even if such outcomes are “by design,” they damage face validity—the immediate plausibility that makes official statistics trusted and adopted.
This is amplified by the National Academies framing: Census is a foundational national dataset, expected to support small jurisdictions and small groups reliably; visible implausibilities can sharply narrow the set of real-world contexts where decision-makers are willing to use the data.10
So the conflict is not merely technical; it is product trust versus privacy tradeoffs under institutional expectations.
3) Consistency Problems (Within Products and Across Products)#
What the Bureau Already Enforces
National Academies describes TDA post-processing constraints such as:
- eliminating negative or fractional counts,
- enforcing additive consistency across geographic hierarchies (e.g., blocks roll up to higher levels),
- preserving some invariants. 10
So the issue is not “the Bureau ignored consistency.” It is that users often want more layers of consistency simultaneously, including:
- Semantic/common-sense consistency (e.g., if occupied then persons > 0)
- Cross-product consistency (e.g., P.L. 94-171 vs DHC where similar concepts are expected to align)
Those demands can conflict with each other and with privacy constraints, and they often imply a stronger “product contract” than the Bureau is willing (or able) to guarantee under DP constraints.
JASON: Why Cross-Product Consistency Becomes a Governance/Policy Issue
JASON is a long-running independent group of senior scientists and engineers that conducts commissioned technical studies for U.S. government agencies; some reports are public while others are classified.
In this context, JASON issued Consistency of Data Products and Formal Privacy Methods for the 2020 Census (JSR-21-02, Jan 11, 2022)—a study the Census Bureau commissioned to analyze how formal-privacy mechanisms (DP-based) affect consistency for P.L. 94-171 and the DHC.34
A central move in the report is to note that the demand for product-to-product consistency is often grounded less in an established theory and more in institutional habit: “Stakeholders are accustomed to receiving the same types of data products that have been historically disseminated” and to treating an official Census statistic as the single “gold standard” number.
At the same time, it explicitly says that—despite sounding compelling—“the theoretical and the technical reasons for needing such consistency remain unclear.”
From there, it advances what it calls the most credible practical rationale: “The most convincing argument … is that” when multiple derivations exist, users may choose values strategically—tempted to “cherry-pick” high numbers in allocation contexts (e.g., grant allocation based on their population) while others search for the lowest, creating unfairness and political/legal conflict.
Crucially, it frames the solution as governance: it agrees the situation could be “chaotic and problematic,” but says it can be prevented if the Bureau provides “clear and definitive guidance,” including “transparent dissemination” of calculations used to derive any “official values,” plus “recommended methods” so it is clear which value should be used when multiple derivations produce inconsistent results.
Importantly, the report is also blunt that resolving these tensions requires policy prioritization, not just better engineering. Two recommendations make the point directly:
- “R1 The Census Bureau should not prioritize consistency, either within or across data products,”
- “R2… minimize the characteristics… released at block level and avoid releasing DHC data at the block level.” The message is not “try harder until everything is consistent,” but that changing the requirements—including product scope at the block level—may be the right lever.
That is why this becomes a product-contract / policy-authority question as much as a technical one: which consistencies are officially guaranteed, which product (or definition) is authoritative when they are not, and what constraints, computation rules, or scope reductions are acceptable to make those guarantees real.
4) Protection Level Versus Accuracy (the “Epsilon Got Bigger” Critique)#
The Census Bureau’s key-parameters release states that the global privacy-loss budget for the P.L. 94-171 redistricting data is ε = 19.61, and that this value is larger than a prior demo setting (ε = 12.2), while noting that data-user feedback played a major role in the decision.37
This is an explicit acknowledgment of shifting toward higher utility (less noise) at the cost of weaker formal guarantees.
National Academies: Utility Improved, but Privacy Guarantees Were Weakened
National Academies notes that the tuning parameter ε was set "much higher than believed protective in past applications of DP noise infusion", with an observed improvement in accuracy for larger geographies/groups, while listing costs including weaker privacy guarantees.10
JASON-Style Framing: Theory Is Sound, but Empirical Disclosure-Risk Reduction Is Under-Quantified
A recurring critique is that:
- Formal privacy provides principled levers (ε, δ, etc.),
- but stakeholders still ask: with this chosen ε, how much disclosure risk was reduced in practice?
Answering that convincingly requires well-designed empirical experiments and disclosure-risk evaluation, not only formal statements.
Two Layers of Argument to Keep Separate
- Formal guarantee layer
- Larger ε implies weaker formal privacy bounds.
- The guarantee does not disappear; the decision is about what upper bound society/institutions are willing to accept.
- Empirical / inferential risk layer
- How much real-world reconstruction or inference risk is reduced at the chosen ε is an empirical question.
- This is where rigorous experiments and transparent evaluation become essential.
What this Means for the “DP Failed?” Verdict
To responsibly conclude “DP failed” (or succeeded) on protection level, the debate needs quantitative evaluation:
- What privacy risk was reduced at ε = 19.61 for the relevant threat model?
- What utility was preserved, for which uses, and at what geographic/population scales?
- How stable are these outcomes across products and time?
Without that, the argument remains largely qualitative—and therefore politically and rhetorically volatile.
Conclusion#
Has DP Failed?#
- Public claims that “DP has failed” largely target the 2020 Census DP-based Disclosure Avoidance System (DAS) and its rollout dynamics, not differential privacy as a mathematical framework.
- As a framework, DP spans multiple variants and design choices; a disappointing deployment does not justify a blanket verdict that DP itself “failed.”
- At the implementation level, many stakeholders experienced material fitness-for-use degradation for small areas and small groups, which can reasonably be judged as product underperformance.
- Reports of implausible outputs and cross-file mismatches (e.g., person vs. housing protection handled separately) damaged face validity and user trust, especially in small geographies.
- “Consistency” demands, particularly across products, are as much governance and product-contract questions as technical ones; JASON emphasizes the need for clear official guidance when multiple derivations diverge.
- Increasing ε (e.g., ε=19.61 for P.L. 94-171) sharpened the utility–privacy tradeoff and fueled dual critiques: “too noisy to use” versus “usable only because privacy was weakened.”
- The most precise characterization is that the product contract and societal implementation of DP-based Census outputs partially broke down, rather than DP as a theory being invalid.
Why perceptions diverge between Japan and the U.S.#
- A different “reference case”
- In the U.S., DP became publicly identified with the decennial Census—a national infrastructure tied directly to funding allocation, redistricting, and civil-rights enforcement.
- Deploying DP there made privacy–utility tradeoffs highly visible and politically charged.
- The debate was often about the “product contract,” not DP theory
- The hardest conflicts centered on what counts as an official number, which use cases are prioritized, and what consistency is guaranteed across tables/products.
- When those expectations were misaligned—or poorly explained—technical tradeoffs were easily summarized as “DP failed.”
- Japan has fewer comparable public flashpoints
- Publicly, Japan has had fewer widely shared incidents where DP was stress-tested in an equally large, politicized public-data system.
- As a result, expectations are more often shaped by theory, research results, and bounded success stories.
- Structural amplifiers in the U.S.
- A multi-stakeholder ecosystem (local governments, NGOs, researchers, political actors), media attention, and litigation pathways make conflicts around official statistics more likely to surface and escalate.
- High expectations for small-area/small-group “face validity” mean small anomalies can quickly become “not usable.”
Bottom line
- The gap is less about DP itself and more about where and how DP was operationalized: the U.S. experience is anchored in a high-stakes, highly scrutinized national deployment, while Japan’s public narrative is anchored more in earlier-stage adoption and narrower applications.
Appendix#
2030 Census#
For 2030, the Census Bureau has already made one foundational call: formal privacy will remain part of the system, including at the most politically sensitive granularity—census blocks. 39 In its 2030 disclosure avoidance research program, the Bureau’s policy committee approved formally private noise injection for block-level total population counts, while also approving a state-level total population invariant.
The Census Bureau is positioning the 2030 Disclosure Avoidance System (DAS) less as a single “algorithm choice” and more as a governed product system: protect confidentiality under formal privacy while preserving practical usability, with continuous stakeholder engagement and iterative evaluation.
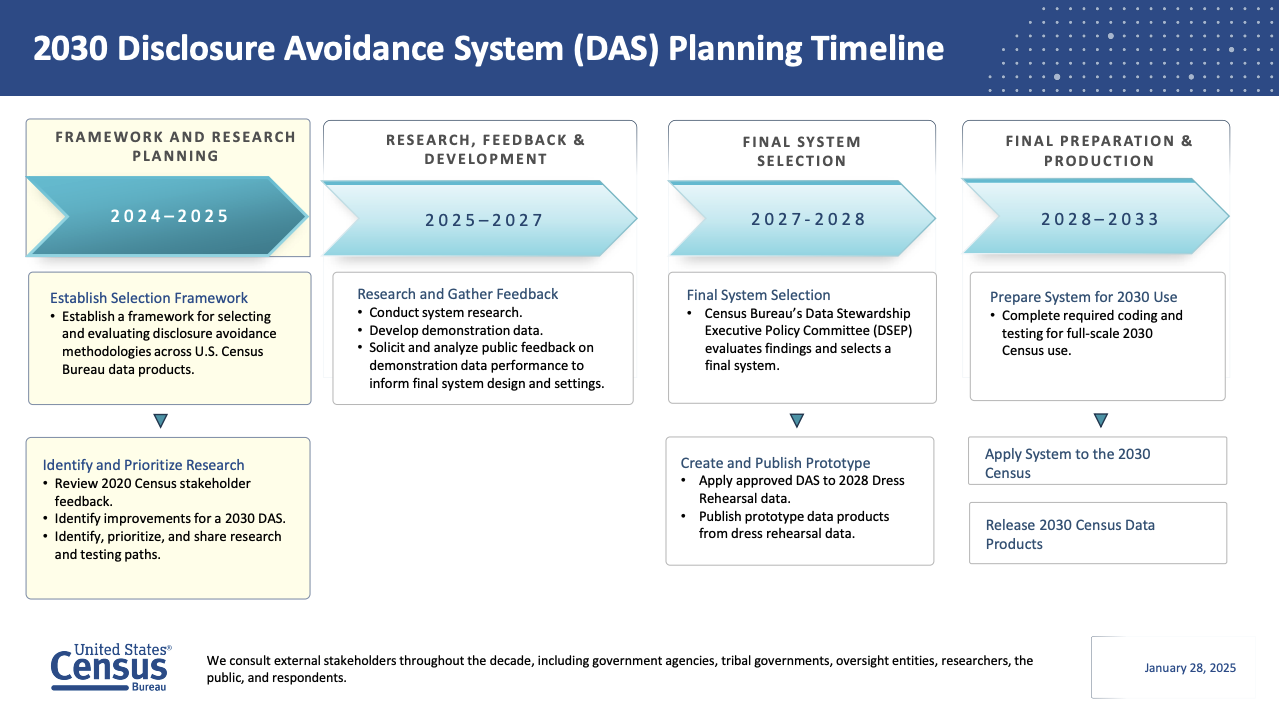
source:40
Within that framework, the plan (as described in the 2030 DA research program materials) lines up directly with the core controversies
- Small-area / small-group utility: The Bureau explicitly prioritizes reducing “disclosure avoidance–related error” for “high-value statistics about small populations,” exploring additional substate statistics, and improving tuning efficiency to allow higher accuracy without reducing protection.
- Implausible / “doesn’t pass the smell test” outputs (face validity): The program explicitly treats the solution space for protecting characteristics/attributes as including “the range (and possible combination) of disclosure avoidance and statistical post-processing solutions.”
- Consistency expectations and governance: “Transparency” is elevated as a core principle—an ideal DAS should “Be transparent.” Beyond that high-level principle, the research agenda includes concrete user-facing governance/support work: “Developing meaningful explanations and measures of disclosure risk,” “Quantifying and communicating the disclosure avoidance-related uncertainty,” and “Developing and curating tools to help data users incorporate” that uncertainty into their uses of census products.
- Protection level skepticism (“is privacy still strong enough?”): The plan makes “risk assessment” a first-class track: ongoing evaluation of evolving threats (including reconstruction-abetted reidentification) and work to specify/evaluate what global and per-attribute confidentiality guarantees can credibly be made.
Synthetic Microdata + Validation Server (Census/ACS)#
During this research, I found this approach particularly compelling.
It may also serve as a meaningful scenario for the PWS Cup.
- The core idea is a tiered-access workflow: publish synthetic microdata for exploration and code development, then use a “gold standard” validation/verification server that runs the same analysis on confidential Census/ACS microdata and returns approved statistics or fidelity diagnostics.
- The Census Bureau already uses this pattern for microdata in practice (e.g., SIPP Synthetic Beta), where researchers work with the synthetic file and can request validation against the confidential “gold standard” process.
- A similar “synthetic-first + validation” protocol exists for establishment data (e.g., SynLBD), where the Bureau validates results on the internal confidential version.
- For ACS, public microdata (PUMS) is geographically limited (down to PUMAs), and Census research has explored ACS-focused synthesis/perturbation; pairing such synthetic ACS microdata with a validation server is a plausible way to expand analytic usability while preserving confidentiality.
References#
Footnotes#
-
NIST. NIST Special Publication 800-226: Differential Privacy Engineering and Applications (PDF). 2025. URL: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-226.pdf ↩ ↩2 ↩3
-
Bun, M., & Steinke, T. Concentrated Differential Privacy: Simplifications, Extensions, and Lower Bounds (arXiv:1605.02065). 2016. URL: https://arxiv.org/abs/1605.02065 ↩
-
Cornell Law School, Legal Information Institute. U.S. Code Title 13, §141 (Population and other census information). n.d. URL: https://www.law.cornell.edu/uscode/text/13/141 ↩
-
U.S. Census Bureau. Redistricting Data Program: Summary Files (Public Law 94-171). n.d. URL: https://www.census.gov/programs-surveys/decennial-census/about/rdo/summary-files.html ↩
-
U.S. Census Bureau. 2020 Census Demographic Profile and Demographic and Housing Characteristics (DHC) File Released (press release). 2023. URL: https://www.census.gov/newsroom/press-releases/2023/2020-census-demographic-profile-and-dhc.html ↩
-
U.S. Census Bureau. 2020 Census Brief C2020BR-12 (PDF). 2020. URL: https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-12.pdf ↩
-
U.S. Census Bureau. 2020 Census Brief C2020BR-05 (PDF). 2020. URL: https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-05.pdf ↩
-
U.S. Census Bureau. 2020 Census Detailed Demographic and Housing Characteristics File B: Technical Documentation (PDF). n.d. URL: https://www2.census.gov/programs-surveys/decennial/2020/technical-documentation/complete-tech-docs/detailed-demographic-and-housing-characteristics-file-b/2020census-detailed-dhc-b-techdoc.pdf ↩
-
U.S. Census Bureau, Center for Economic Studies. CED Working Paper 2024-006 (PDF). 2024. URL: https://www2.census.gov/library/working-papers/2024/adrm/ced/ced-wp-2024-006.pdf ↩
-
National Academies of Sciences, Engineering, and Medicine. Assessing the 2020 Census: Final Report (Chapter 14). n.d. URL: https://www.nationalacademies.org/read/27150/chapter/14 ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 ↩9
-
U.S. Census Bureau. 2020 Census Data Products: Release Schedule Update (press release). 2023. URL: https://www.census.gov/newsroom/press-releases/2023/2020-census-data-products.html ↩
-
U.S. Census Bureau. 2020 Census Disclosure Avoidance Handbook (PDF). 2020. URL: https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf ↩ ↩2 ↩3 ↩4 ↩5
-
U.S. Census Bureau. Disclosure Avoidance System (DAS) training workshop transcript: 2021-05-13 (PDF). 2021. URL: https://www2.census.gov/about/training-workshops/2021/2021-05-13-das-transcript.pdf ↩ ↩2
-
U.S. Census Bureau. Disclosure Avoidance System (DAS) training workshop presentation: 2021-05-13 (PDF). 2021. URL: https://www2.census.gov/about/training-workshops/2021/2021-05-13-das-presentation.pdf ↩ ↩2
-
U.S. Census Bureau. 2020 Census Brief C2020BR-04 (PDF). 2020. URL: https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-04.pdf ↩ ↩2
-
U.S. Census Bureau. 2020 Census Brief C2020BR-03 (PDF). 2020. URL: https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-03.pdf ↩ ↩2 ↩3
-
U.S. Census Bureau. JSM 2018 presentation: Database Reconstruction (PDF). 2018. URL: https://www.census.gov/content/dam/Census/newsroom/press-kits/2018/jsm/jsm-presentation-database-reconstruction.pdf ↩
-
U.S. Census Bureau. Research Report Series 2012-13 (Re-identification risks in public data) (PDF). 2012. URL: https://www.census.gov/content/dam/Census/library/working-papers/2012/adrm/rrs2012-13.pdf ↩
-
U.S. Census Bureau (CED/ADRM). Reidentification studies (PDF). 2019 (revised 2021-03-31 in filename). URL: https://www2.census.gov/adrm/CED/Papers/CY19/2019-04-Reidentification%20studies-20210331FinRed.pdf ↩
-
U.S. Census Bureau, Research Matters blog. Balancing privacy and accuracy… (blog post). 2019-10. URL: https://www.census.gov/newsroom/blogs/research-matters/2019/10/balancing_privacyan.html ↩
-
U.S. Census Bureau. Comparing differential privacy with older disclosure avoidance methods (factsheet, PDF). 2021. URL: https://www.census.gov/content/dam/Census/library/factsheets/2021/comparing-differential-privacy-with-older-disclosure-avoidance-methods.pdf ↩
-
U.S. Census Bureau. Research agenda for the 2030 Census Disclosure Avoidance System (presentation, PDF). 2025-06-23. URL: https://www2.census.gov/about/training-workshops/2025/2025-06-23-research-agenda-for-2030-census-disclosure-avoidance-system-presentation.pdf ↩
-
U.S. Census Bureau. Disclosure Avoidance System (DAS) development timeline (PDF). n.d. URL: https://www2.census.gov/programs-surveys/decennial/2020/program-management/data-product-planning/disclosure-avoidance-system/das-development-timeline.pdf ↩
-
U.S. Census Bureau, Census Advisory Committee (NAC). Recommendations (September 2022 meeting materials) (PDF). 2022-09. URL: https://www2.census.gov/about/partners/cac/nac/meetings/2022-09/recommendations.pdf ↩
-
U.S. Census Bureau, Random Samplings blog. 2020 Census data products: next steps (blog post). 2022-04. URL: https://www.census.gov/newsroom/blogs/random-samplings/2022/04/2020-census-data-products-next-steps.html ↩
-
Associated Press. Article on Census differential privacy controversy (AP News). 2019. URL: https://apnews.com/article/5e28a198f03cd8eec1c3e34bdc56fe6c ↩
-
The Washington Post. Article on 2020 Census differential privacy / IPUMS (coverage). 2021-06-01. URL: https://www.washingtonpost.com/local/social-issues/2020-census-differential-privacy-ipums/2021/06/01/6c94b46e-c30d-11eb-93f5-ee9558eecf4b_story.html ↩
-
Associated Press. Article referencing Census differential privacy / redistricting impacts (AP News). 2021. URL: https://apnews.com/article/religion-wisconsin-new-york-tampa-florida-68c96e7eb701da74ae7c8df3c3476705 ↩
-
The Markup. Will new privacy changes protect census data — or make things worse? 2021-05-11. URL: https://themarkup.org/the-breakdown/2021/05/11/will-new-privacy-changes-protect-census-data-or-make-things-worse ↩
-
San Francisco Chronicle. Article on detailed Census data and differential privacy (coverage). 2021. URL: https://www.sfchronicle.com/us-world/article/The-most-detailed-data-about-the-US-population-in-16378154.php ↩
-
Garfinkel, S. (MIT SERC / PubPub). Differential Privacy and the 2020 U.S. Census (release/essay). n.d. URL: https://mit-serc.pubpub.org/pub/differential-privacy-2020-us-census/release/2 ↩
-
U.S. Census Bureau. Developing the 2020 Disclosure Avoidance System (DAS) (web page). n.d. URL: https://www.census.gov/programs-surveys/decennial-census/decade/2020/planning-management/process/disclosure-avoidance/2020-das-development.html ↩
-
Abowd, J. M., Ashmead, R., Cumin, D., Menon, S., Garfinkel, S. L., et al. (U.S. Census Bureau / CED). The 2020 Census Disclosure Avoidance System TopDown Algorithm (Final pre-print, 2022-04-07) (PDF). URL: https://www2.census.gov/adrm/CED/Papers/CY22/2022-002-AbowdAshmeadCumingMenonGarfinkelEtal.pdf ↩
-
U.S. Census Bureau. 2020 Census Data Products: Privacy Methods (PDF; includes JASON-related references). n.d. URL: https://www2.census.gov/programs-surveys/decennial/2020/program-management/planning-docs/2020-census-data-products-privacy-methods.pdf ↩ ↩2
-
U.S. Census Bureau. Protecting the confidentiality of the 2020 Census redistricting data (factsheet, PDF). 2021. URL: https://www.census.gov/content/dam/Census/library/factsheets/2021/protecting-the-confidentiality-of-the-2020-census-redistricting-data.pdf ↩ ↩2 ↩3
-
U.S. Census Bureau (GovDelivery bulletin). Bulletin 2cb745b (web bulletin). n.d. URL: https://content.govdelivery.com/accounts/USCENSUS/bulletins/2cb745b ↩
-
U.S. Census Bureau. 2020 Census Redistricting Data: Key Parameters and Privacy Protection (press release). 2021. URL: https://www.census.gov/newsroom/press-releases/2021/2020-census-key-parameters.html ↩ ↩2
-
U.S. Census Bureau. 2020 Census Brief C2020BR-08 (PDF). 2020. URL: https://www2.census.gov/library/publications/decennial/2020/census-briefs/c2020br-08.pdf ↩
-
U.S. Census Bureau, Research Matters blog. 2030 Census disclosure avoidance (formal privacy) (blog post). 2025. URL: https://www.census.gov/newsroom/blogs/research-matters/2025/2030-census-disclosure-avoidance.html ↩
-
U.S. Census Bureau. 2030 Census Disclosure Avoidance System timeline (PDF). n.d. URL: https://www.census.gov/content/dam/Census/programs-surveys/decennial/2030-census/disclosure-avoidance/2030-census-das-timeline.pdf ↩